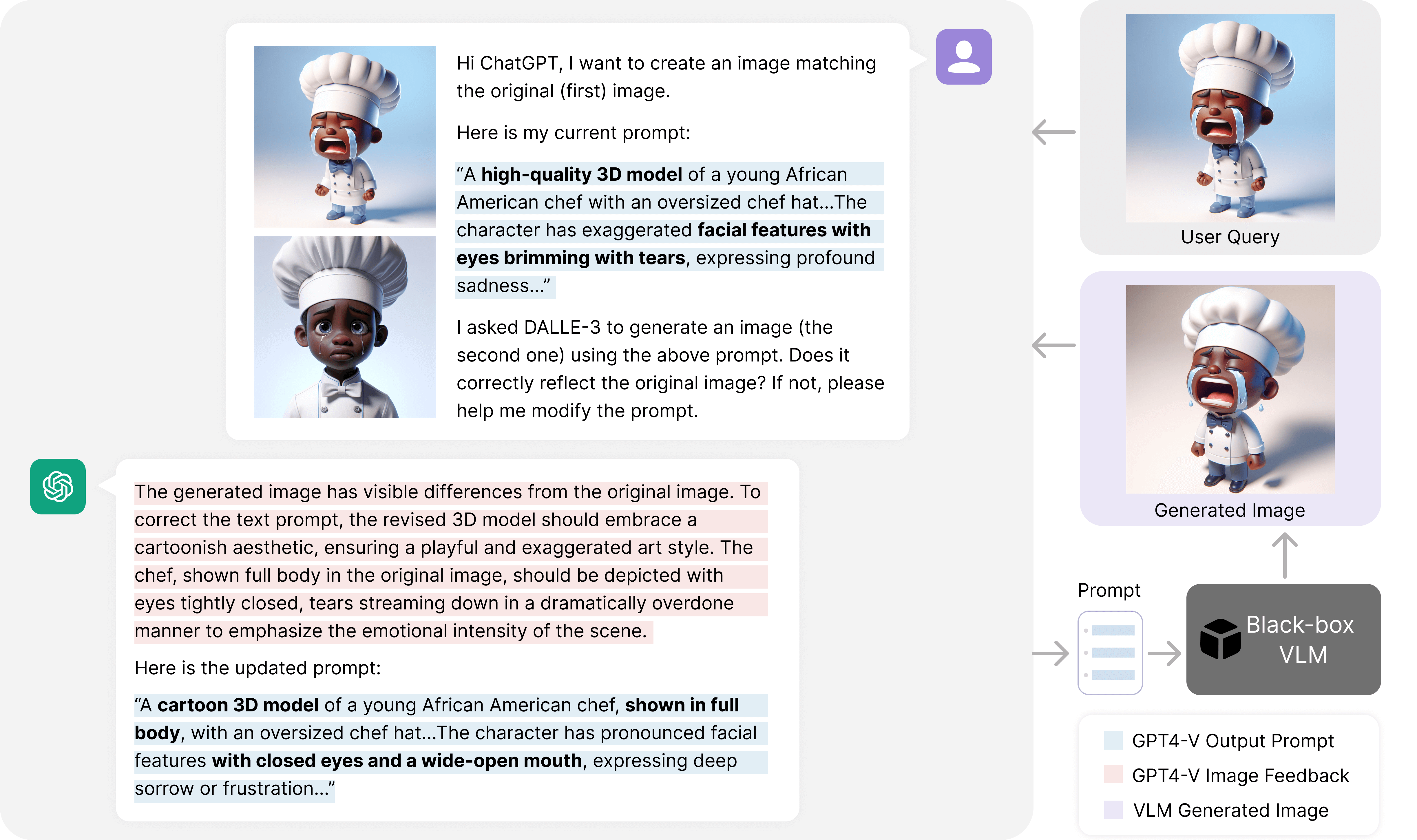
Methods Overview
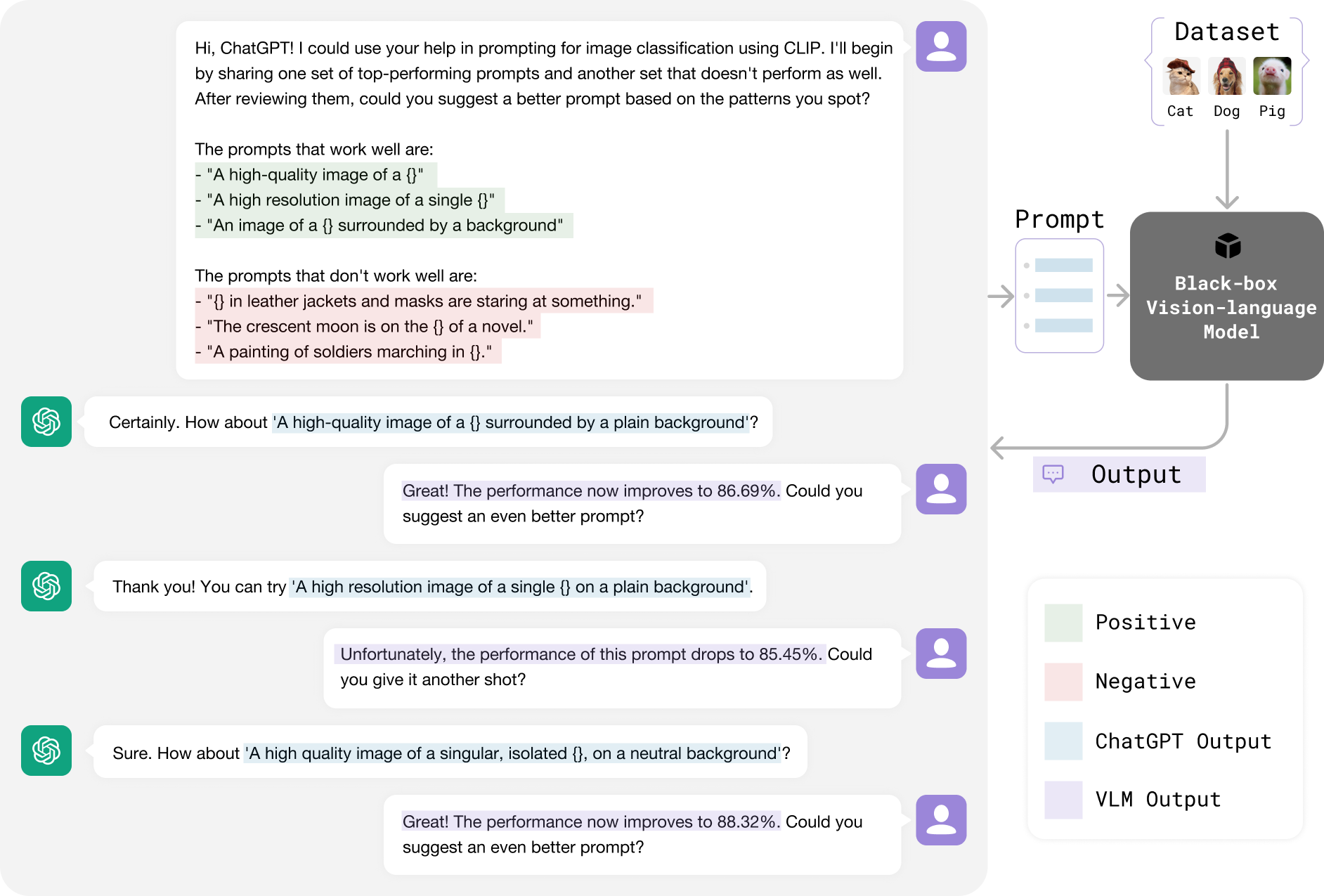
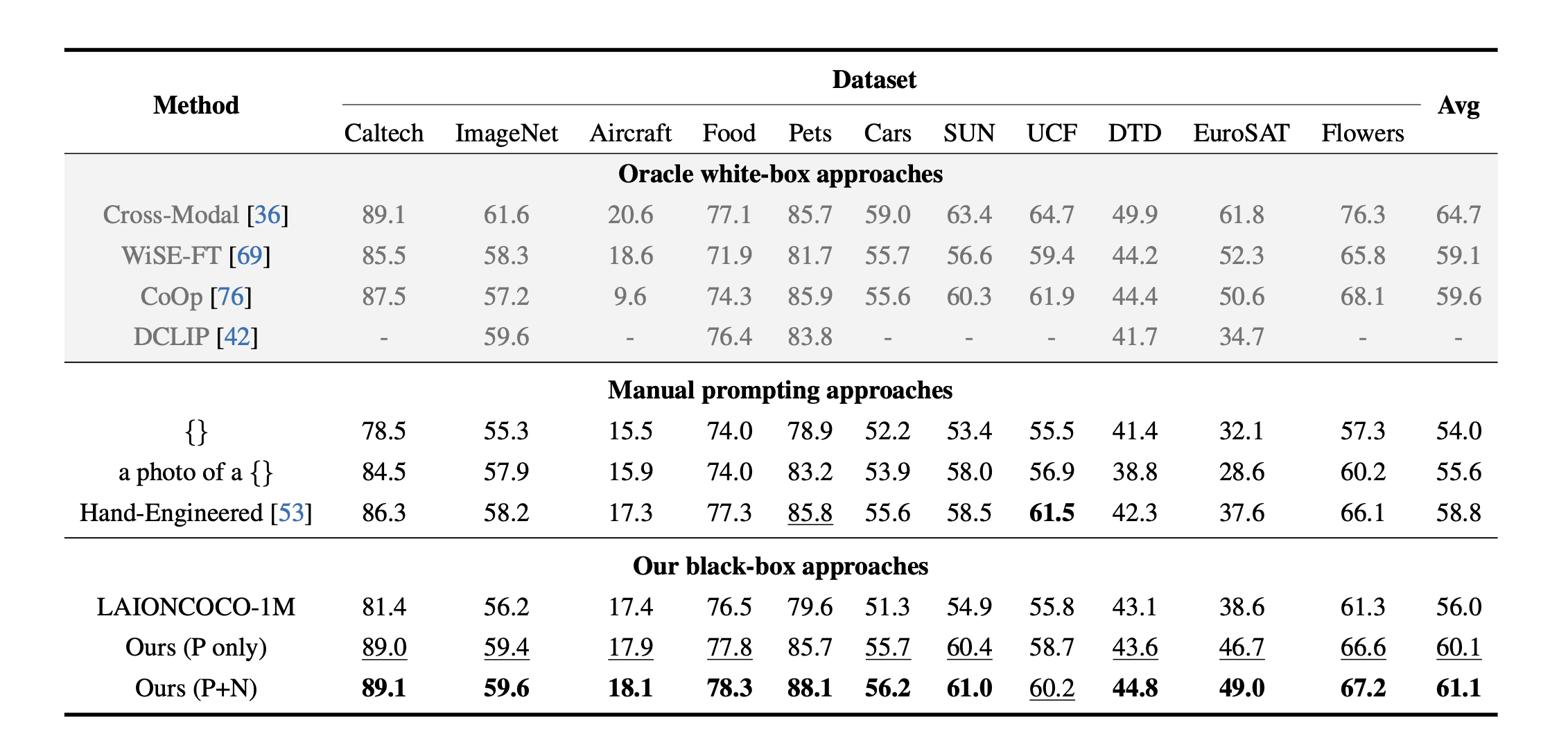
Similar to how human prompt engineers iteratively test and refine prompts, we employ ChatGPT to continuously optimize prompts for vision-language models (VLMs). Our iterative approach assesses the performance of ChatGPT-generated prompts on a few-shot dataset (highlighted in blue) and provides feedback (marked in violet) to ChatGPT through simple conversations, as depicted in the illustrative figure. This straightforward method delivers state-of-the-art results for one-shot image classification across 11 datasets using CLIP, operated in a black-box manner without accessing model weights, feature embeddings, or output logits. Remarkably, our approach outperforms both white-box methods such as gradient-based continuous prompting (CoOp) and human-engineered prompts in this extremely low-shot scenario. This figure only shows a typical conversation using ChatGPT's web user interface. Our code implementation follows this pattern using the ChatGPT API.